{kind=link}
{kind=link}
A parallelized PNG encoder in Rust
by Brion Vibber brion@pobox.com
Compressing PNG files is a relatively slow operation at large image sizes, and can take from half a second to over a second for 4K resolution and beyond. See my blog post series on the subject for more details.
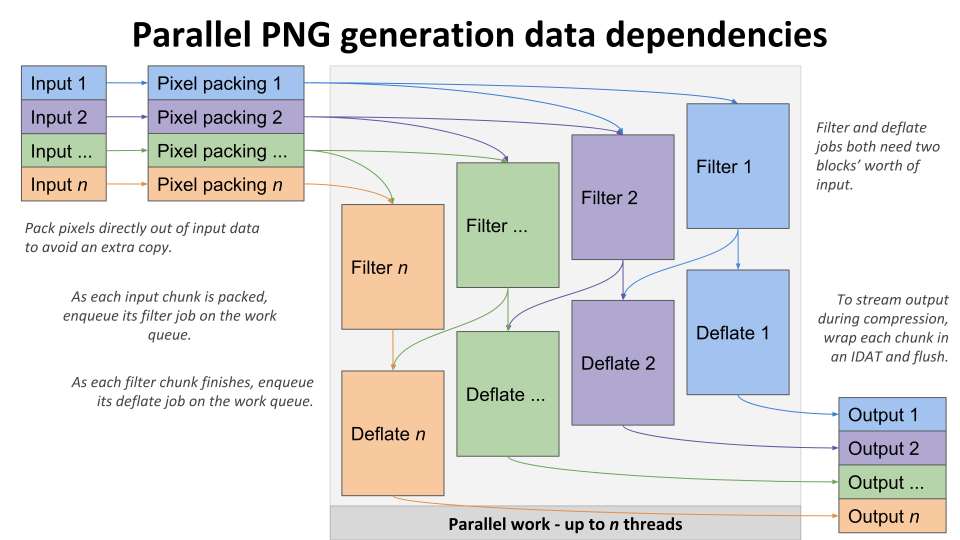
The biggest CPU costs in traditional libpng seem to be the filtering, which is easy to parallelize, and the deflate compression, which can be parallelized in chunks at a slight loss of compression between block boundaries.
pigz is a well-known C implementation of parallelized deflate/gzip compression, and was a strong inspiration for the chunking scheme used here.
I was also inspired by an experimental C++/OpenMP project called png-parallel by Pascal Beyeler, which didn't implement filtering but confirmed the basic theory.
Creates correct files in all color formats (input must be pre-packed). Performs well on large files, but needs work for small files and ancillary chunks. Planning API stability soon, but not yet there -- things will change before 1.0.
Performance: * ☑️ MUST be faster than libpng when multi-threaded * ☑️ SHOULD be as fast as or faster than libpng when single-threaded
Functionality: * ☑️ MUST support all standard color types and depths * ☑️ MUST support all standard filter modes * ☑️ MUST compress within a few percent as well as libpng * MAY achieve better compression than libpng, but MUST NOT do so at the cost of performance * ☑️ SHOULD support streaming output * MAY support interlacing
Compatibility: * MUST have a good Rust API (in progress) * MUST have a good C API (in progress) * ☑️ MUST work on Linux x86, x8664 * ☑️ MUST work on Linux arm, arm64 * ☑️ SHOULD work on macOS x8664 * ☑️ SHOULD work on iOS arm64 * ☑️ SHOULD work on Windows x86, x86_64 * ☑️️ SHOULD work on Windows arm64
Compression ratio is a tiny fraction worse than libpng with the dual-4K screenshot and the arch photo at the current default 256 KiB chunk size, getting closer the larger you increase it.
Using a smaller chunk size, or enabling streaming mode, will increase the file size slightly more in exchange for greater parallelism (small chunks) and lower latency to bytes hitting the wire (streaming).
Note that unoptimized debug builds are about 50x slower than optimized release builds. Always run with --release!
As of September 26, 2018 with Rust 1.29.0, single-threaded performance on Linux x8664 is ~30-40% faster than libpng saving the same dual-4K screenshot sample image on Linux and macOS x8664. Using multiple threads consistently beats libpng by a lot, and scales reasonably well at least to 8 physical cores.
Times for re-encoding the dual-4K screenshot at default options:
``` MacBook Pro 13" 2015 5th-gen Core i7 3.1 GHz 2 cores + Hyper-Threading
Linux x86_64: - libpng gcc -- 850 ms (target to beat) - libpng clang -- 900 ms - mtpng @ 1 thread -- 555 ms -- 1.0x (victory!) - mtpng @ 2 threads -- 302 ms -- 1.8x - mtpng @ 4 threads -- 248 ms -- 2.2x (HT)
macOS x86_64: - libpng clang -- 943 ms (slower than Linux/gcc) - mtpng @ 1 thread -- 563 ms -- 1.0x (nice!) - mtpng @ 2 threads -- 299 ms -- 1.9x - mtpng @ 4 threads -- 252 ms -- 2.2x (HT) ```
macOS and Linux x86_64 perform about the same on the same machine, but libpng on macOS is built with clang, which seems to optimize libpng's filters worse than gcc does. This means we beat libpng on macOS by a larger margin than on Linux, where it's usually built with gcc.
``` Refurbed old Dell workstation Xeon E5520 2.26 GHz 2x 4 cores + Hyper-Threading configured for SMP (NUMA disabled)
Linux x86_64: - libpng gcc -- 1695 ms (target to beat) - mtpng @ 1 thread -- 1124 ms -- 1.0x (winning!) - mtpng @ 2 threads -- 570 ms -- 2.0x - mtpng @ 4 threads -- 298 ms -- 3.8x - mtpng @ 8 threads -- 165 ms -- 6.8x - mtpng @ 16 threads -- 155 ms -- 7.3x (HT)
Windows 10 x86_64: - mtpng @ 1 thread -- 1377 ms -- 1.0x - mtpng @ 2 threads -- 708 ms -- 1.9x - mtpng @ 4 threads -- 375 ms -- 3.7x - mtpng @ 8 threads -- 214 ms -- 6.4x - mtpng @ 16 threads -- 170 ms -- 8.1x (HT)
Windows 10 i686: - mtpng @ 1 thread -- 1524 ms -- 1.0x - mtpng @ 2 threads -- 801 ms -- 1.9x - mtpng @ 4 threads -- 405 ms -- 3.8x - mtpng @ 8 threads -- 243 ms -- 6.3x - mtpng @ 16 threads -- 194 ms -- 7.9x ```
Windows seems a little slower than Linux on the same machine, not quite sure why. The Linux build runs on Windows 10's WSL compatibility layer slightly slower than native Linux but faster than native Windows.
32-bit builds are a bit slower still, but I don't have a Windows libpng comparison handy.
``` Raspberry Pi 3B+ Cortex A53 1.4 GHz 4 cores
Linux armhf (Raspian): - libpng gcc -- 5368 ms - mtpng @ 1 thread -- 6068 ms -- 1.0x - mtpng @ 2 threads -- 3126 ms -- 1.9x - mtpng @ 4 threads -- 1875 ms -- 3.2x
Linux aarch64 (Fedora 29): - libpng gcc -- 4692 ms - mtpng @ 1 thread -- 4311 ms -- 1.0x - mtpng @ 2 threads -- 2140 ms -- 2.0x - mtpng @ 4 threads -- 1416 ms -- 3.0x ```
On 32-bit ARM we don't quite beat libpng single-threaded, but multi-threaded still does well. 64-bit ARM does better, perhaps because libpng is less optimized there. Note this machine throttles aggressively if it heats up, making the second run of a repeat on a long file like that noticeably slower than the first.
``` iPhone X A11 2.39 GHz 6 cores (2 big, 4 little)
iOS aarch64: - mtpng @ 1 thread -- 802 ms -- 1.0x - mtpng @ 2 threads -- 475 ms -- 1.7x - mtpng @ 4 threads -- 371 ms -- 2.2x - mtpng @ 6 threads -- 320 ms -- 2.5x ```
A high-end 64-bit ARM system is quite a bit faster! It scales ok to 2 cores, getting smaller but real benefits from scheduling further work on the additional little cores.
``` Lenovo C630 Yoga Snapdragon 850 2.96 GHz 8 cores (4 big, 4 little?)
Windows Subsystem for Linux aarch64 (Win10 1903): - mtpng @ 1 thread -- 1029ms -- 1.0x - mtpng @ 2 threads -- 516ms -- 2.0x - mtpng @ 4 threads -- 317ms -- 3.2x - mtpng @ 6 threads -- 262ms -- 3.9x - mtpng @ 8 threads -- 241ms -- 4.3x ```
The Snapdragon 850 scores not as well as the A11 in single-threaded, but catches up with additional threads.
See the projects list on GitHub for active details.
Encoding can be broken into many parallel blocks:
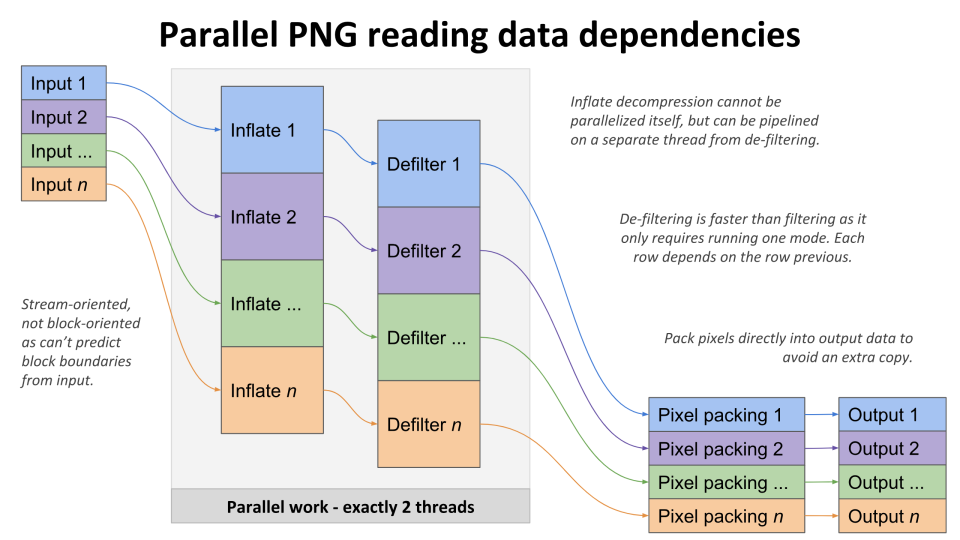
Decoding cannot; it must be run as a stream, but can pipeline.
Rayon is used for its ThreadPool implementation. You can create an encoder using either the default Rayon global pool or a custom ThreadPool instance.
crc is used for calculating PNG chunk checksums.
libz-sys is used to wrap libz for the deflate compression. I briefly looked at pure-Rust implementations but couldn't find any supporting raw stream output, dictionary setting, and flushing to byte boundaries without closing the stream.
itertools is used to manage iteration in the filters.
png is used by the CLI tool to load input files to recompress for testing.
clap is used by the CLI tool to handle option parsing and help display.
time is used by the CLI tool to time compression.
typenum is used to do compile-time constant specialization via generics.
You may use this software under the following MIT-style license:
Copyright (c) 2018 Brion Vibber
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.