A fast Minimum-Weight Perfect Matching (MWPM) solver for Quantum Error Correction (QEC)
Please see our tutorial for a quick explanation and some Python demos.
MWPM decoders are widely known for its high accuracy [1] and several optimizations that further improves its accuracy [2]. However, there weren't many publications that improve the speed of the MWPM decoder over the past 10 years. Fowler implemented an $O(N)$ asymptotic complexity MWPM decoder in [3] and proposed an $O(1)$ complexity parallel MWPM decoder in [4], but none of these are publicly available to our best knowledge. Higgott implemented a fast but approximate MWPM decoder (namely "local matching") with roughly $O(N)$ complexity in [5]. With recent experiments of successful QEC on real hardware, it's time for a fast and accurate MWPM decoder to become available to the community.
Our idea comes from our study on the Union-Find (UF) decoder [6]. UF decoder is a fast decoder with $O(N)$ worst-case time complexity, at the cost of being less accurate compared to the MWPM decoder. Inspired by the Fowler's diagram [3], we found a relationship between the UF decoder [7]. This nice animation (press space to trigger animation) could help people see the analogy between UF and MWPM decoders. With this interpretation, we're able to combind the strength of UF and MWPM decoders together.
We shall note that Oscar Higgott and Craig Gidney independently reach the same approach of using sparse decoding graph to solve MWPM more efficiently in PyMatching V2 [8]. It's impressive to see that they have much better single-thread performance than fusion-blossom (about 5x-20x speedup). They use more optimizations like priority queue and single-tree strategy that appears in existing literature of blossom algorithms (possibly some other novel techniques, looking forward to their paper!). Also, they use C++ language rather than Rust programming language. Rust enforces memory safety which adds some runtime overhead (like vector boundary check and unnecessary locks in parallel programming). We use unsafe Rust to improve the speed by 1.5x-3x but these features are not yet enabled in the Python library and only available when using the native Rust library. In fact, PyMatching V2's optimizations and fusion-blossom's parallel computation (fusion operation) are compatible with each other. With their impressive work, we're looking forward to another 5x-20x speed of the parallel MWPM decoder if combined together. For now, user should use PyMatching for better CPU efficiency in large-scale simulations, and use fusion-blossom library as an educational tool with visualization tool and entry-level tutorials.
We highly suggest you watch through several demos here to get a sense of how the algorithm works. All our demos are captured from real algorithm execution. In fact, we're showing you the visualized debugger tool we wrote for fusion blossom. The demo is a 3D website and you can control the view point as you like.
For more details of why it finds an exact MWPM, please read our paper [coming soon 💪].
Click the demo image below to view the corresponding demo
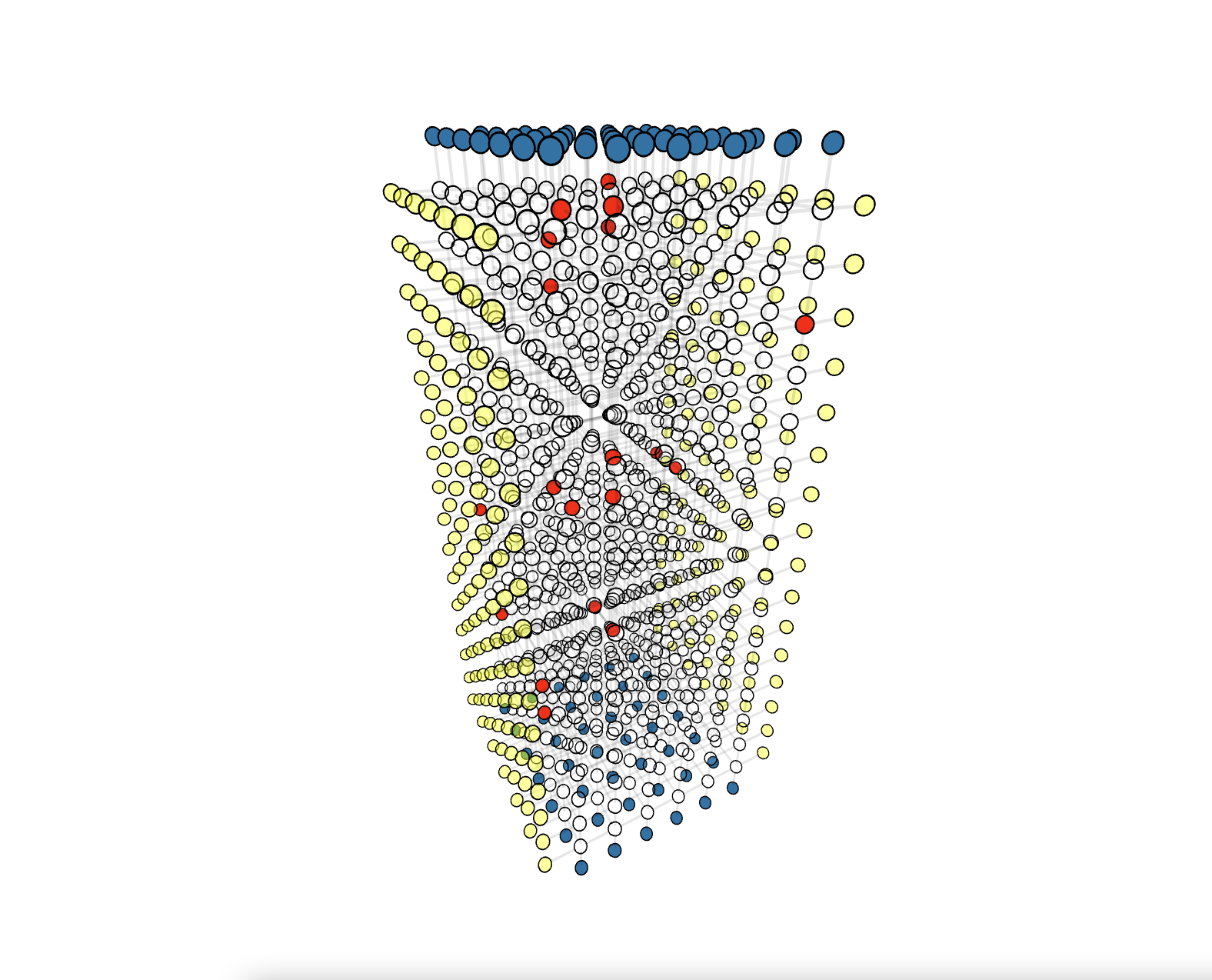
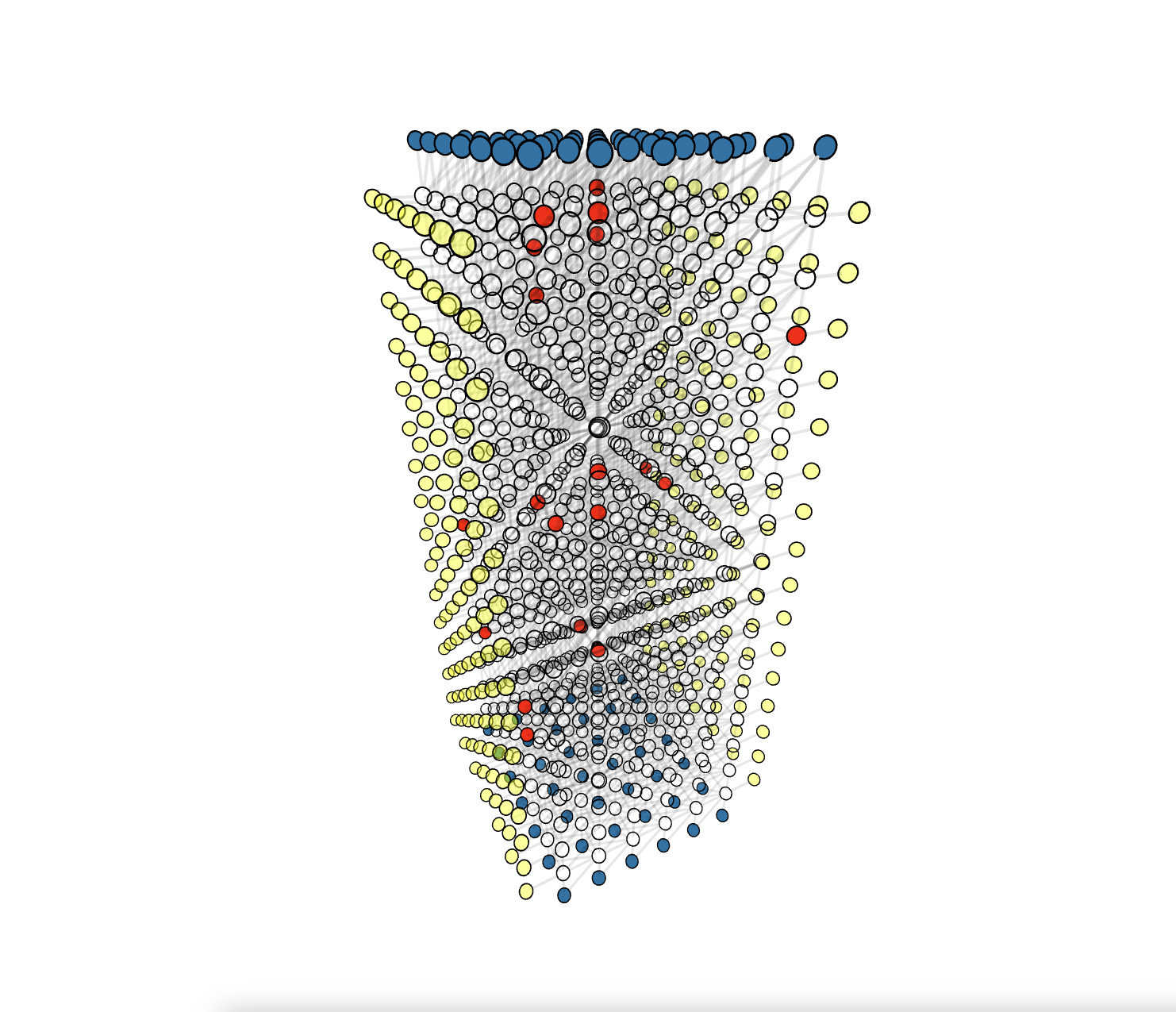
Our code is written in Rust programming language for speed and memory safety, but it's hardly a easy language to learn. To make the decoder more accessible, we bind the library to Python and user can simply install the library using pip3 install fusion-blossom.
We have several Python demos at the tutorial website . Also there is a simple example for decoder, and you can run it by cloning the project and run python3 scripts/demo.py.
For parallel solver, it needs user to provide a partition strategy. Please wait for our paper for a thorough description of how partition works.
We use Intel(R) Xeon(R) Platinum 8375C CPU for evaluation, with 64 physical cores and 128 threads. Note that Apple m1max CPU has roughly 2x single-core decoding speed, but it has limited number of cores so we do not use data from m1max. The benchmark scripts can be found in benchmark folder, running in Rust native binary (not the Python package, which has fewer optimization features enabled). By default, we test phenomenological noise model with $p$ = 0.005, code distance $d$ = 21, planar code with $d(d-1)$ = 420 $Z$ stabilizers, 100000 measurement rounds.
First of all, the number of partitions will effect the speed. Intuitively, the more partitions there are, the more overhead because fusing two partitions consumes more computation than solving them as a whole. But in practice, memory access is not always at the same speed. If cache cannot hold the data, then solving big partition may consume even more time than solving small ones. We test on a single-thread decoder, and try different partition numbers. At partition number = 2000, we get roughly the minimum decoding time of 2.4us per defect vertex. This corresponds to each partition hosting 50 measurement rounds (decoding blocks of 49 * 21 * 20).

Given the optimal partition number of a single thread, we keep the partition number the same and try increasing the number of threads. Note that the partition number may not be optimal for large number of threads, but even in this case, we reach 41x speed up given 64 physical cores. The decoding time is pushed to 58ns per sydnrome or 0.7us per measurement round. This can catch up with the 1us measurement round of a superconducting circuit. Interestingly, we found that hyperthreading won't help much in this case, perhaps because this decoder is memory-bounded, meaning memory throughput is the bottleneck. Although the number of defect vertices is only a small portion, they are randomly distributed so every time a new syndrome is given, the memory is almost always cold and incur large cache miss panelty.

In the above figure, I also benchmarked PyMatching V2 using exactly the same decoding graph (benchmark script here), with batch decoding optimization and excluding initialization time. It's indeed faster than fusion blossom on a single thread, but not as much as I expected. As tested in stim, the speed difference is 10x to 100x depending on the specific configuration. Then I run extensive benchmark by adjusting the measurement round from 1 to 1e5, and found the reason. Fusion blossom, even running on a single CPU, can partition the decoding graph and run the divide-and-conquer algorithm to reach strict $O(1)$ decoding time per defect vertex given more and more measurement rounds $T$. PyMatching V2, on the other hand, shows a slightly increasing decoding time perhaps because of less memory locality with larger decoding graph. Indeed, as shown below, PyMatching V2 is 33x faster than fusion-blossom when $T=1$. But as $T$ grows, this gap becomes smaller, because each base partition handles no more than 50 measurement rounds with Fusion Blossom technique. In a conclusion, it would be beneficial to combine PyMatching V2 and fusion-blossom together, even for just running on a single thread.

In order to understand the bottleneck of parallel execution, we wrote a visualization tool to display the execution windows of base partitions and fusion operations on multiple threads. Blue blocks is the base partition and green blocks is the fusion operation. Fusion operation only scales with the size of the fusion boundary and the depth of active partitions, irrelevant to the base partition's size. We'll study different partition and fusion strategies in our paper. Below shows the parallel execution on 64 threads. Blue blocks are base partitions, each is a 49 * 21 * 20 decoding graph block. Green blocks are fusion blocks, each is a 1 * 21 * 20 decoding graph block sandwiched by two neighbor base partitions. You can click the image which jumps to this interactive visualization tool.

The weights in QEC decoding graph are computed by taking the log of error probability, e.g. $we = \log{(1-p)/p}$ or roughly $we = -\log{p}$, we can safely use integers to save weights by e.g. multiplying the weights by 1e6 and truncate to nearest integer. In this way, the truncation error $\Delta w_e = 1$ of integer weights corresponds to relative error $\Delta p /{p}=10^{-6}$ which is small enough. Suppose physical error rate $p$ is in the range of a positive f64 variable (2.2e-308 to 1), the maximum weight is 7e7,which is well below the maximum value of a u32 variable (4.3e9). Since weights only sum up in our algorithm (no multiplication), u32 is large enough and accurate enough. By default we use usize which is platform dependent (usually 64 bits), but you can
We use integer also for ease of migrating to FPGA implementation. In order to fit more vertices into a single FPGA, it's necessary to reduce the resource usage for each vertex. Integers are much cheaper than floating-point numbers, and also it allows flexible trade-off between resource usage and accuracy, e.g. if all weights are equal, we can simply use a 2 bit integer.
Note that other libraries of MWPM solver like Blossom V also default to integer weights as well. Although one can change the macro to use floating-point weights, it's not recommended because "the code may even get stuck due to rounding errors".
Here is an example installation on Ubuntu20.04.
```sh
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
sudo apt install build-essential ```
In order to test the correctness of our MWPM solver, we need a ground-truth MWPM solver. Blossom V is widely-used in existing MWPM decoders, but according to the license we cannot embed it in this library. To run the test cases with ground truth comparison or enable the functions like blossom_v_mwpm, you need to download this library at this website to a folder named blossomV at the root directory of this git repo.
shell
wget -c https://pub.ist.ac.at/~vnk/software/blossom5-v2.05.src.tar.gz -O - | tar -xz
cp -r blossom5-v2.05.src/* blossomV/
rm -r blossom5-v2.05.src
To start a server, run the following ```sh cd visualize npm install # to download packages
node index.js
cd .. cargo test visualizepaperweightedunionfind_decoder -- --nocapture ```
This project is funded by NSF MRI: Development of PARAGON: Control Instrument for Post NISQ Quantum Computing
[1] Fowler, Austin G., et al. "Topological code autotune." Physical Review X 2.4 (2012): 041003.
[2] Criger, Ben, and Imran Ashraf. "Multi-path summation for decoding 2D topological codes." Quantum 2 (2018): 102.
[3] Fowler, Austin G., Adam C. Whiteside, and Lloyd CL Hollenberg. "Towards practical classical processing for the surface code: timing analysis." Physical Review A 86.4 (2012): 042313.
[4] Fowler, Austin G. "Minimum weight perfect matching of fault-tolerant topological quantum error correction in average $ O (1) $ parallel time." arXiv preprint arXiv:1307.1740 (2013).
[5] Higgott, Oscar. "PyMatching: A Python package for decoding quantum codes with minimum-weight perfect matching." ACM Transactions on Quantum Computing 3.3 (2022): 1-16.
[6] Delfosse, Nicolas, and Naomi H. Nickerson. "Almost-linear time decoding algorithm for topological codes." Quantum 5 (2021): 595.
[7] Wu, Yue. APS 2022 March Meeting Talk "Interpretation of Union-Find Decoder on Weighted Graphs and Application to XZZX Surface Code". Slides: https://us.wuyue98.cn/aps2022, Video: https://youtu.be/BbhqUHKPdQk
[8] Higgott, Oscar. PyMatching v2 https://github.com/oscarhiggott/PyMatching